03-1. 크롤링
1. 정의
인터넷(SNS, 웹사이트 등)에서 정보 수집
2. 크롤링 종류
- API 기반 정보 수집: 프로그램을 위한 정보 제공 API가 존재
- 스크레이핑: 인간 사용자를 위해 제공된 웹페이지를 파싱하여 활용
3. API 기반 크롤링
1) Naver crawling (비 로그인 형)
a. 개발자 센터 가입: http://developers.naver.com
NAVER Developers
네이버 오픈 API들을 활용해 개발자들이 다양한 애플리케이션을 개발할 수 있도록 API 가이드와 SDK를 제공합니다. 제공중인 오픈 API에는 네이버 로그인, 검색, 단축URL, 캡차를 비롯 기계번역, 음
developers.naver.com
b. 애플리케이션 생성 과정
- 상단바에서 App 누르고 Application 누르기
- Application 등록 누르고 애플리케이션 이름 정하기, 사용 API에서 검색 API 선택하기, 환경에서 웹 선택하기
- 웹 선택하면 나오는 URL에 http://localhost 쓰기
- 완성하면 나오는 화면은 아래와 같음
- 어플리케이션 정보에 id와 키 있음
c. key와 id 값
import os
import sys
import datetime
import time
import json
# 반드시 자기 id 로 넣기
client_id = #문자열로 자신의 앱의 아이디 넣기
client_secret = #문자열로 자신의 앱의 키 넣기
LEC=Trued. 네이버 크롤링 프로그램 구조
getRequestUrl() -> getNaverSearch() -> getPostData() 순서대로 호출하기

e. urllib 호출 부분
헤더에 id, secret 포함하여 api url에 get요청으로 접근한다.
import urllib.request
def getRequestUrl(url):
req = urllib.request.Request(url)
req.add_header("X-Naver-Client-Id", client_id)
req.add_header("X-Naver-Client-Secret", client_secret)
try:
response = urllib.request.urlopen(req)
if response.getcode() == 200:
print ("[%s] Url Request Success" % datetime.datetime.now())
return response.read().decode('utf-8')
except Exception as e:
print(e)
print("[%s] Error for URL : %s" % (datetime.datetime.now(), url))
return Nonef. url 구성 및 호출
네이버 오픈API 종류 - Open API 가이드
네이버 오픈API 종류 네이버 오픈API는 인증 여부에 따라 로그인 방식 오픈 API와 비로그인 방식 오픈 API로 구분됩니다. 로그인 방식 오픈 API 로그인 방식 오픈 API는 '네이버 로그인'의 인증을 받아
developers.naver.com
- 뉴스 검색 API: 한 번에 100개, 최대 1,000개까지 가능

- 뉴스 검색 API를 활용하여 네이버에 챗gpt 검색하기
- q에 검색하고자 하는 검색어를 quote()의 인자로 넣으면 됨(quote(): 아스키코드 형식이 아닌 글자를 URL로 인코딩해줌)
- url의 display= 의 숫자에 원하는 결과물 개수를 적어주면 됨
if LEC:
q= urllib.parse.quote("챗GPT") # url coding
url = "https://openapi.naver.com/v1/search/news.json?query=%s&display=5"%q
print (url)
resp = getRequestUrl(url)
#display 뒤에 붙은 숫자가 가져오는 결과의 개수
print (resp)- getNaverSearch 사용하여 검색
url의 형식은 해당 페이지 참조(https://developers.naver.com/docs/serviceapi/search/news/news.md)
def getNaverSearch(svc, srcText, start, display):
base = "https://openapi.naver.com/v1/search"
svc = "/%s.json" % svc
parameters = "?query=%s&start=%s&display=%s" % (urllib.parse.quote(srcText), start, display)
url = base + svc + parameters
responseDecode = getRequestUrl(url)
if (responseDecode == None):
return None
else:
return json.loads(responseDecode) # json decode
if LEC:
result = getNaverSearch("news", "챗GPT", 10, 2)
print(result)- 결과 가공
json 구조로부터 필요한 필드만을 추출, 필요한 형태로 변환 => list로 return
def getPostData( resultJ, resultL):
for item in resultJ['items'] :
#변환
pDate = datetime.datetime.strptime(item['pubDate'], '%a, %d %b %Y %H:%M:%S +0900')
pDate = pDate.strftime('%Y-%m-%d')
#필드 추출
resultL.append( [ item['title'], item['description'], item['originallink'], pDate])
print (len(resultL))
if LEC:
resultL=[]
resultJ=getNaverSearch("news", 인공지능, 1, 6)
getPostData(resultJ, resultL)
print(resultL)- 전체 프로그램
def main():
svc = 'news' # 크롤링 할 대상 : news, blog, encyc, shop
srcText = input('검색어를 입력하세요: ')
resultL=[]
start=1
while True:
jsonResponse = getNaverSearch(svc, srcText, start, 100)
if jsonResponse == None:
break
getPostData(jsonResponse, resultL)
start+=100
if (start > 1000) :
break
print("가져온 데이터 : %d 건" %len( resultL))
if __name__ == '__main__':
main()
2) Facebook API 활용 (로그인 형)
- OAuth: 특정 사용자의 동의를 얻어 사용자의 정보를 가져오는데, API에서 사용자 인증 후 동의를 얻는데 사용
- 기본 구조: user token 확보 (동의했을 시) -> api에 user token을 포함하여 호출
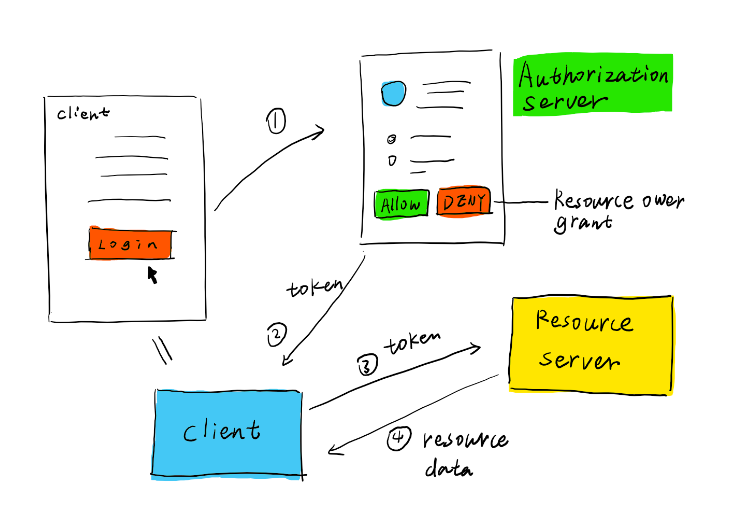
a. 개발자 등록, app 등록
- facebook 계정 생성 이후 https://developers.facebook.com/apps/create 에서 앱 생성
로그인 또는 가입하여 보기
Facebook에서 게시물, 사진 등을 확인하세요.
www.facebook.com
b. 앱 생성 과정
- 앱 만들기: 앱 유형을 없음으로, 기본 정보 제공에 항목들 작성
- 앱 목록에서 테스트앱 만들기: 모든 권한을 테스트해볼 수 있음 //만약 테스트앱이 아닌 경우, 검수를 받아야 함
c. API 테스트: API 탐색기
- 메뉴-도구-그래프 API 탐색기 순으로 진입
- 권한 추가: public_profile 선택(유저 프로필 중 email, user_gender, user_birthday, user_age_range 을 포함하게 함)
d. generate access token 실행: 본인을 대상 사용자로서 토큰 받기
e. python code
그래프 API - 문서 - Meta for Developers
Facebook 사용자이고 계정 로그인에 문제가 있다면 고객 센터를 방문하세요. 그래프 API 그래프 API는 앱에서 Facebook 소셜 그래프를 읽고 쓰는 기본 수단입니다. 모든 SDK 및 제품은 그래프 API와 일정
developers.facebook.com
API Reference — Facebook SDK for Python 4.0.0-pre documentation
This page contains specific information on the SDK’s classes, methods and functions. class facebook.GraphAPI A client for the Facebook Graph API. The Graph API is made up of the objects or nodes in Facebook (e.g., people, pages, events, photos) and the c
facebook-sdk.readthedocs.io
발급받은 token으로 자신의 정보 가져오기
import urllib3
import facebook
import requests
token='토큰 적기'
graph = facebook.GraphAPI(access_token=token)
profile = graph.request('me?fields=id,name,birthday, age_range, email')
print (profile)
#이름 출력할 때
print(profile['name'])
#이메일 출력할 때
print(profile['email'])